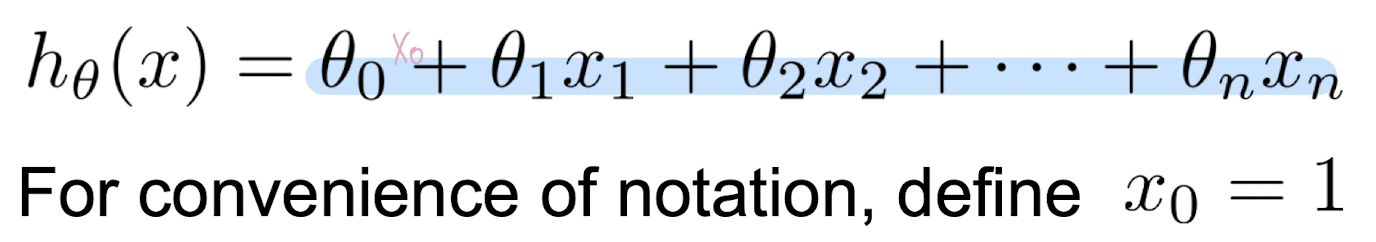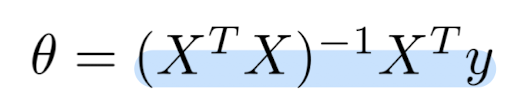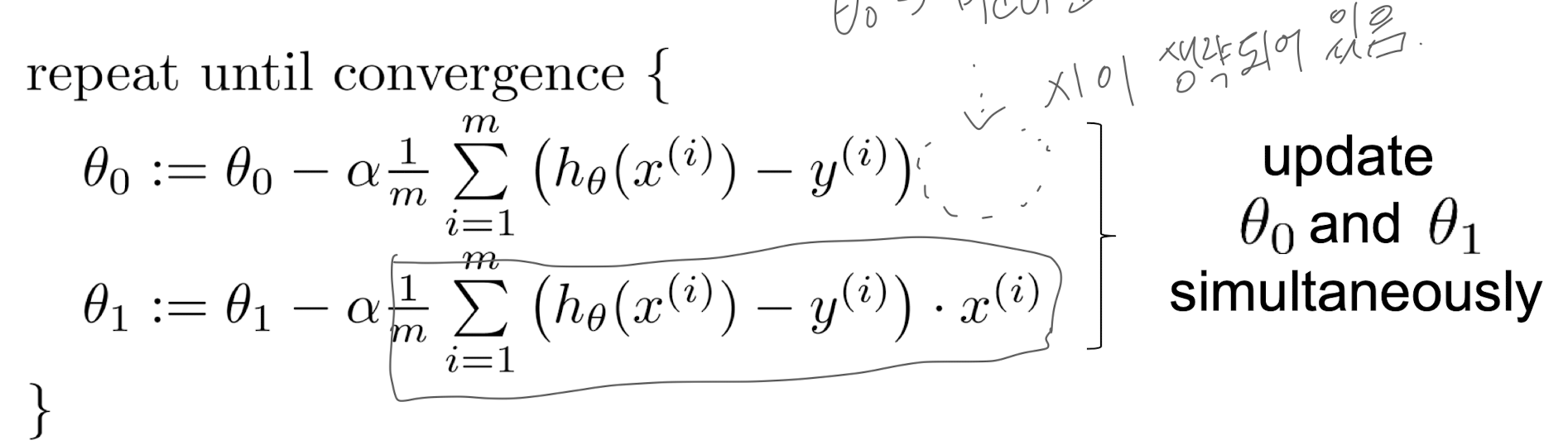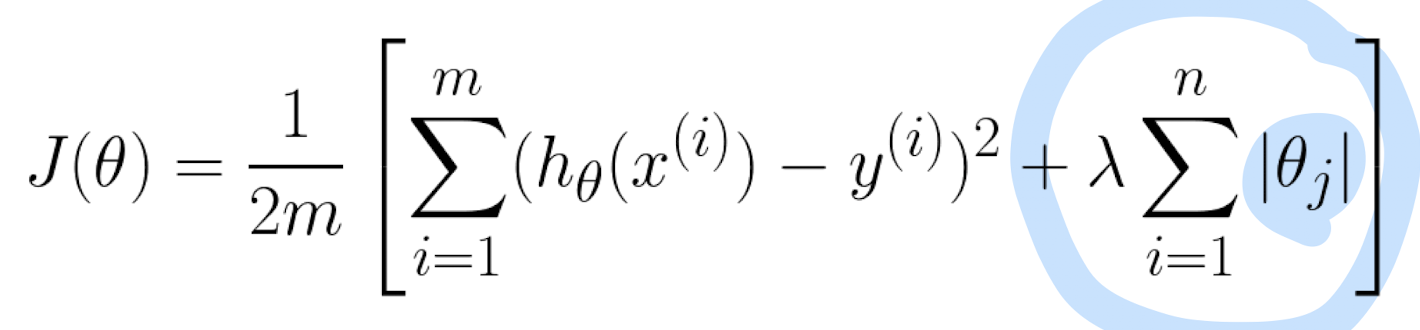Big Data Intro
- 2003년 전까지 5 엑사바이트의 정보를 생산했음
- 이제 이틀마다 5 엑사바이트의 정보를 생산 -> 빅데이터
Big Data의 4V
- Volume
- Variety
- Velocity
- Veracity
Science Paradigms
- 몇천 년 전: 과학은 empirical 했다. -> 자연 현상을 서술
- 몇백 년 전: theoretical branch -> 이론, 모델링
- 몇십 년 전: computational -> 시뮬레이션
- 오늘날: data exploration
- 미래: Data-driven Science -> Data-driven Hypothesis Generation
Big Data Challenges
- 빅데이터
* 크고 복잡한 데이터
* 예: social, web, financial transaction data, academic articles, genomic data...
- 2가지의 고난
* 효율적 저장 및 접근
* Data Analytics -> 가치 있는 정보 캐내기
Data Science and Big data
- 빅데이터라는 용어는 거대한 데이터셋의 분석을 뜻함
- 예: 트위터/페이스북 전체, 주요 사이트의 웹 로그, 몇천 명의 genome sequence, Flickr의 전체 이미지...
- 크기가 커지면 데이터를 다루기 더 어려워진다
Big data as Bad data
- Unrepresentative participation (bias): 인스타그램-젊은 층만 이용, 뉴욕타임즈-자유주의적, Fox News-보수적, 월스트리트저널-부자만 봄
- Spam and machine-generated content: 봇, 가짜뉴스 등
- Power-laws: redundancy를 의미 -> 건물 탐지 태스크를 수행할 때, 랜드마크 데이터는 많으므로 랜드마크만 잘 인식하고 일반 건물은 잘 인식하지 못할 수 있음
- Susceptibility to temporal bias (ex. Google Flu Trends): 구글의 자동완성 기능이 검색 쿼리의 분포를 변화시킴
Large-Scale Machine Learning
- 우리가 지금까지 공부한 알고리즘들은 아주 큰 데이터셋에 잘 맞지 않는다.
- 아주 큰 데이터셋에 대해서는 파라미터가 적은 모델이 잘 작동하지 않는다.
- 알고리즘의 시간복잡도가 linear -> O(n)이어야 한다.
- Big matrices는 빅데이터에 대해 희소할 수 있다.
* 예) 넷플릭스 고객 1억명을 대상으로 전체 영화에 대한 유저 평점 matrix를 분석한다고 했을 때 차원이 아주 크고 희소하다.
-> 모든 사람이 모든 영화를 보지는 못하기 때문에
Filtering Data -> domain specific criteria
- 빅데이터의 장점은 분석을 더 깔끔하게 하기 위해서 빅데이터의 상당 부분을 버려도 된다는 것이다.
- 예: 트위터의 전체 트윗 중 34%만이 영어권 계정 -> 나머지는 버려도 됨
- irrelevant or hard-to-interpret data를 필터링 하는 것은 application-specific knowledge를 필요로 한다.
Subsampling Data
- subsampling...?
* training/validation/testing data를 깔끔하게 분리할 수 있다.
* 단순하고 튼튼한 모델은 파라미터가 적음 -> big data의 overkill 유도
cf) hyperparameter fitting, 모델 선정->여러번 학습
* 스프레드시트 사이즈의 데이터셋은 분석이 쉽고 빠르게 된다.
절단(truncation)을 이용하기
- 첫 n개의 기록만을 취하는 것은 쉽지만 여러 오류를 범할 수 있다.
* temporal biases (오래된 데이터만을 분석하게 될 수도)
* lexicographic biases (A에 대한 데이터만 분석하게 될 수도 -> Arabic은 분석범위에 있지만 Korean은 포함되지 않을 수 있다)
* numerical biases (ID 번호 같은 건 무작위 부여가 아니라 의미가 있는 숫자일 수 있음)
Stream Sampling
- n을 모를 때 size k 짜리 균일 샘플을 추구할 때가 있다.
- 해결책: k개의 active element에 대한 배열을 유지하고, n번쨰 요소를 k/n의 확률로 대체 -> 들어왔던 것도 쫓겨날 수도 있음
- cut을 만들 때 새로운 요소의 위치를 랜덤으로 선정할 수 있음.
Distributed vs. Parallel Processing
- Parallel processing: 1개의 기계에서 진행 (스레드, 운영체제 프로세스 등을 통해)
- Distributed processing: 여러 개의 기계에서 진행 - 네트워크 통신 등을 이용
Data Paralllelism
- parallelism을 이용하는 방법은 빅데이터를 다수의 기계로 나눠 독립적으로 모델을 학습시키는 것이다.
- k-means처럼 각각의 결과를 합치기가 어렵다.
* Parallelized K-means
예를 들어 100개의 seed가 있는 상황이라고 하면
1. 1개의 master machine (job assign...)이 k개의 random seed를 선정해서 다른 machine에게 broadcast
2. local에서, 각 machine은 자신이 가진 데이터가 어느 클러스터에 속하는지 계산한다.
3. 그 데이터로부터 새로운 centroid, data #를 계산하여 전달한다. (sum vector 등의 형태로 전달하면 일일이 전달할 필요가 없다)
4. master machine이 그 정보를 전달받아 centroid 값을 최종적으로 업데이트하고, 이를 다시 broadcast한다.
5. 계속 반복한다.
Grid Search
- 정의: right hyper-parameter를 찾는 것
- 예: k-means clustering에서 올바른 k값을 찾는 것
- parallel하게 실행될 경우 최적의 값을 찾아낼 수 있다.
Distributed processing의 복잡도
- machine 수에 따라 급격하게 증가한다
* 1개: 나의 box의 중심부를 바쁘게 함
* 2개: 몇 개의 box에 대해 프로그램을 실행시킨다.
* 여러개: MapReduce 등의 시스템을 이용하여 효율적으로 관리할 수 있다.
MapReduce / Hadoop
- distributed computing을 위한 구글의 MapReduce 패러다임은 Hadoop, Spark 등의 오픈소스로 구현됨
- 간단한 parallel programming model
- 수백/수천 개의 기계에 대해 Straightforward scaling
- redundancy(여분)을 통한 fault tolerance
Divide and Conquer
1. 분할(partition): 하나의 일을 여러 개로 쪼갬
2. 각각 수행
3. 병합(combine): 각각의 결과를 하나로 합침
Typical Big Data Problem
- 아주 큰 숫자의 기록을 반복
- 각각에서 관심있는 것을 뽑아내기
- 중간 결과를 shuffle, sort
- 중간 결과를 집합
- 최종 결과를 도출
- word counting, k-means clustering을 생각해보기
MapReduce의 아이디어
- Scale Out: 여러 개의 기계를 붙이기 (up-> 기계 성능 장체를 올리는 것->X)
* 스케일 업은 메모리 bottleneck 현상 등이 발생할 위험이 있다.
- Move processing to the data: 클러스터들이 제한된 bandwidth를 가진다
- 순차적으로 데이터를 처리하고, 랜덤 접근을 피하라: seek은 비용이 많이 들지만, disk throughput은 합리적
* HDD 등에서 데이터를 읽을 때 head를 이동해가며 읽는다. 이것을 어떻게 최적화하느냐?
Components of Hadoop
1. Hadoop/MapReduce
- 분산된 빅데이터 처리 인프라구조
- abstract/paradigm
- fault-tolerant: 데이터를 100개로 나누어주는데, 그중 1개의 처리기가 고장나면 일단 재시작부터 함 -> 그래도 동작하지 않을 경우 다른 처리기에게 할당
- schedule: job assignment 등을 조율
- execution
2. HDFS (Hadoop Distributed File System)
- fault-tolerant: 하드디스크가 망가져도 괜찮음
- high-bandwidth
- high availability distributed storage
- 최소 3개의 복사본은 유지
MapReduce Word Count
- Map and Reduce 함수
map(k,v) -> [(k', v')]
reduce(k', [v']) -> [(k',v')]- Word Count
Map(String docid, String text):
for each word w in text:
Emit(w, 1);
Reduce(String term, Iterator<int> values):
int sum = 0;
for each v in values:
sum += v;
Emit(term, sum);
MapReduce 실행 시간
- scheduling 조절: map, reduce task를 수행하도록 worker에 부여
- 데이터 분산 조절: 프로세스에서 데이터로 이동
- synchronization 조절: intermediate data의 수집, 정렬, 혼합
- error, fault 조절: worker failure 감지 및 재시작
Hadoop Distributed File System (HDFS)
- 클러스터 내부의 노드의 local disk에 데이터 저장 -> 메모리의 모든 데이터를 갖고 있을 RAM이 충분하지 않음
- Disk access는 느리지만 disk throughput은 합리적 -> file을 통한 linear scan은 괜찮음
- 모든 데이터를 3번 복제 -> reliability on commodity hardware
Cloud Computing Services
- Amazon 등의 플랫폼은 단기 작업에 대한 여러 machine 제공 가능
Feel Free to Experiment: micro instance의 경우 해볼 만함