

Data Science Analysis Pipeline
- Modeling: 예측을 할 수 있는 도구로 정보를 감싸는 과정
- 핵심 과정: building, fitting, validating the model
Philosophies of Modeling
1. Occam's Razor
- 14세기 영국 수도승
- 뜻: 가장 단순한 설명이 가장 좋다.
- 가장 적은 가정을 만드는 답을 선택해야 한다. -> 모델에서 parameter의 수를 줄여야 함을 의미
- LASSO/ridge regression 등의 머신러닝 기법은 피쳐를 최소화하기 위해 penalty function을 사용 -> 불필요한 coefficient를 최소화
2. Bias-Variance Tradeoffs
- "모든 모델은 틀리다. 그렇지만 어떤 모델은 유용하다."
- Bias: 모델에서 에러가 있는 가정으로부터 생성된 오류 -> underfitting; 가정 자체가 정답에서 멀어져 있는 경우 -> linear로 변환됨
- Variance: training set 안의 작은 변화에 민감함으로써 생기는 오류 -> overfitting; 가정 자체는 맞으나 변수의 퍼진 정도가 너무 큰 경우

3. Principles of Nate Silver
- 확률에 기반하여 생각하기
- 새로운 정보에 반응하여 예측을 바꾸기
- consensus를 추구하기
나의 모델에 대한 결과
- 모델로부터 1개의 결정론적인 예측을 요구하는 것은 불가능한 일이다.
- 좋은 예측 모델은 모든 가능한 경우에 대한 확률 분포를 제공
- logistic regression, k-nearest neighbor 등의 머신러닝 모델
Live Models
- 새로운 정보에 반응하여 에측을 꾸준히 변경하면 Live한 모델이라고 한다.
- 에측이 정확한 답으로 수렴하는가? / 이전 예측을 보여줘서 모델의 일관성을 판단할 수 있게 하는가? / 모델이 더 최근 데이터로 다시 학습되는가?
Consensus 추구
- Google Flue Trends: illness term에 대한 검색 빈도를 이용하여 flu 발생을 예측 -> 구글이 검색 제안 기능을 도입하고 실패함
- 비교 가능한 경쟁 예측이 있는가? / baseline model이 하는 말이 무엇인가? / 예측을 하는 접근 방법이 서로 다른 여러 개의 모델을 사용하는가?
- Boosting, Bagging: 분류기의 ensemble을 명시적으로 합하는 머신러닝 기술
Taxonomy of Models
1. Linear vs. Non-linear Model
- Linear: 각각의 피쳐 변수를 coefficient로 중요도를 나타내는 식으로 나타냄 -> 이러한 값들을 더해 점수를 계산함
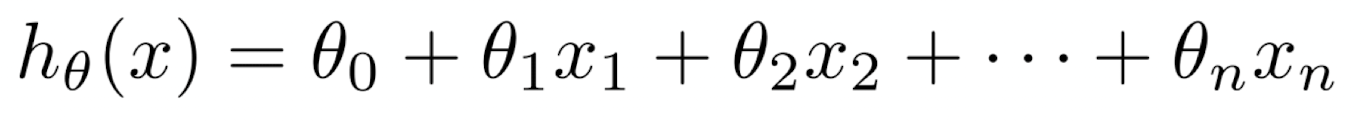
- Non-linear: 고차원의 polynomial, logarithm, exponential 등을 포함하는 식
2. Blackbox vs. Descriptive Model
- 모델은 대부분 설명적임 = 왜 그러한 결정을 내렸는지 설명함
- Linear regression model이 그 예시, 트리도 예시일 수 있음.
- Neural Network Model은 왜 그러한 결정을 내렸는지 알 수 없음.
-> opaque
3. First principle vs. Data-driven Model
- First principle: 시스템이 작동하는 방법에 대한 이론적인 설명을 기반으로 함 -> 시뮬레이션, 과학 공식
- Data-driven: input parameter와 outcome variables 사이의 관측된 데이터 상관성 -> 대부분의 기계학습 모델
- 좋은 모델은 둘을 적절히 섞었을 때 나옴
4. General vs. Ad Hoc Model
- 분류나 회귀 등의 머신러닝 모델은 general = 문제에 특정되는 아이디어가 아닌 특정 데이터만을 기반으로 함
- Ad Hoc Model은 특정 도메인의 지식을 이용 - 특별한 목적
5. Stochastic vs. deterministic
6. Flat vs. Hierarchical
모델평가 : Baseline
- simplest reasonable models to compare against
- 대표적인 예시 (복잡도 오름차순)
* uniform/random selection among labels
* training data의 가장 흔한 label
* 가장 성능이 좋은 single-variable model
* 이전 시간 포인트와 같은 label
* mean, median
* linear regression
* existing model: SOTA model...
- baseline 모델은 공정해야한다.
분류기 평가
- 이진 분류기에 의한 결과는 총 4가지가 나올 수 있음

Threshold Classifiers
- 적절한 threshold를 찾는 것이 중요

Accuracy
- 전체 예측에 대한 옳은 예측의 비율

- Accuracy가 높다고 하더라도 실제의 결과와는 차이가 있는 경우가 있으므로 정확도만으로 비교하는 것은 옳지 않다
- |P| << |N| 일 때 특히 부정확
Precision

Recall

F-score

- 조화평균은 산술평균보다 항상 작거나 같으므로 F-score가 높아지는 것을 방지
- 두 개의 점수가 높아야 최종적으로 F 값도 높아짐
Sensitivity vs. Specificity
- Sensitivity: True Positive Rate - 민감도
- Specificity: True Negative Rate - 특이도
- 암환자, 스팸 등에서 true label이 무엇인지는 내용의 긍부정이 아니라 우리가 타겟으로 하는 대상의 여부에 달린 것
종합적으로는!
- Accuracy: class size가 대체로 다를 때 잘못된 결과를 낳음
- Recall: 분류기가 균형이 잡혀있을 때 정확도와 같은 값이 됨
- High precision: 균형 잡히지 않은 class size에 대해서는 매우 달성하기 어려움
- F-score: 어떤 단일 통계량에 대해서는 좋은 결과를 냄, but 4개 값이 모두 분류기의 성능에 대해 설명할 수 있음
Receiver-Operator Characteristic (ROC) curves
- threshold 값이 바뀌면 recall/precision, TPR/FPR 값이 변한다.
- ROC curve 아래의 면적 = AUC는 정확도 판단 기준이 됨
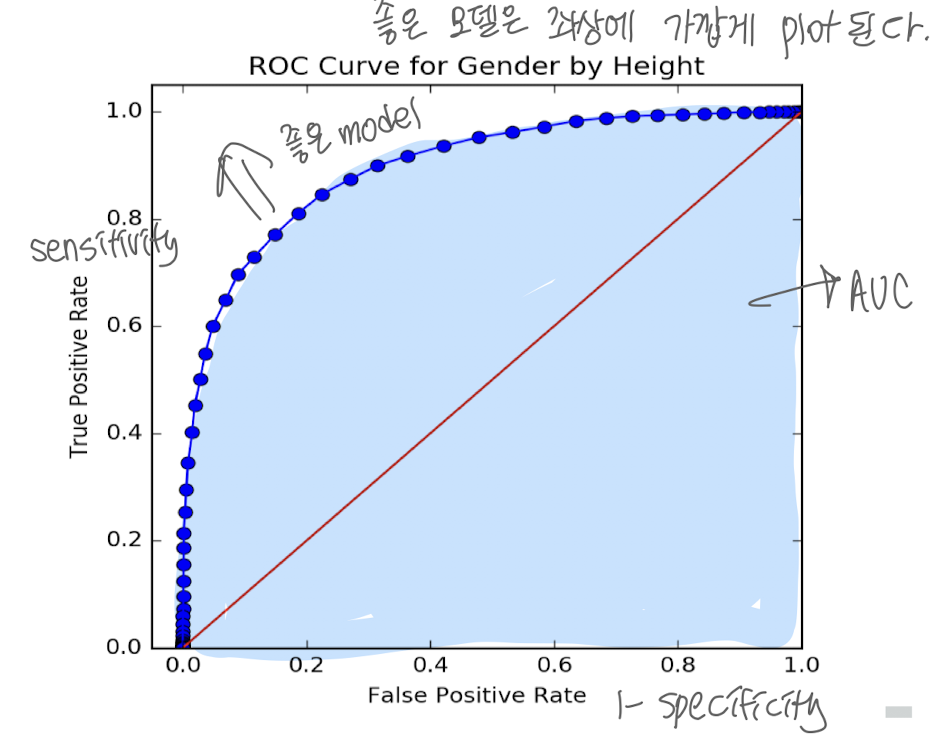
복수 분류 시스템 평가
- class가 많아지면 분류가 더 어려워짐
- top-k success rate: first k개의 예측에 대해 성공할 경우 보상을 제공
(검색 결과: 예측한 가장 가능성이 높은 N개의 클래스와 동일한 실제 클래스의 표준 정확도)
Summary statistics: Numerical Error
- f: forecast, o: observation
- absolute error: (f-o)
- relative error: (f-o)/o -> 더 나은 결과
- 오류를 나타내는 여러 방법
* Mean or median squared error (MSE)

* Root mean squared error

Error histograms

Evaluation Data
- out-of-sample prediction: 모델을 만들 때 본 적 없었던 데이터를 이용하여 결과를 도출
- training 60%, validation 20%, testing 20% 이런 식으로 데이터를 분할
- testing data는 다른 경우에 절대 보면 안 되고 딱 테스트 할 때만 볼 수 있도록 해야함.
Sins in evaluation
- training / test data를 서로 섞었는가?
- 나의 implementation에 오류가 있는가?
- 이러한 질문을 던져서 오류를 찾을 수 있다.
Cross-validation
- 데이터가 충분하지 않을 경우, 데이터를 k개로 쪼개서 k-1번째 데이터에 대해 학습을 진행, 나머지로 평가, 그리고 다른 데이터 조각으로 계속 반복
- limiting case: leave one out validation
- k-fold




