

Exploratory Data Analysis
- 데이터를 자세히 살펴보는 것이 중요한 이유
* 데이터 수집, 전처리에서의 실수 구별
* 통계적 가정을 어기는 경우를 파악
* 데이터 패턴 탐색
* 가설 설정
Anscombe's Quartet
- 같은 평균, 편차, 상관관계, 회귀직선을 가지지만 데이터의 분포 모양 자체가 매우 달라질 수 있음.
Mapping Data to Image
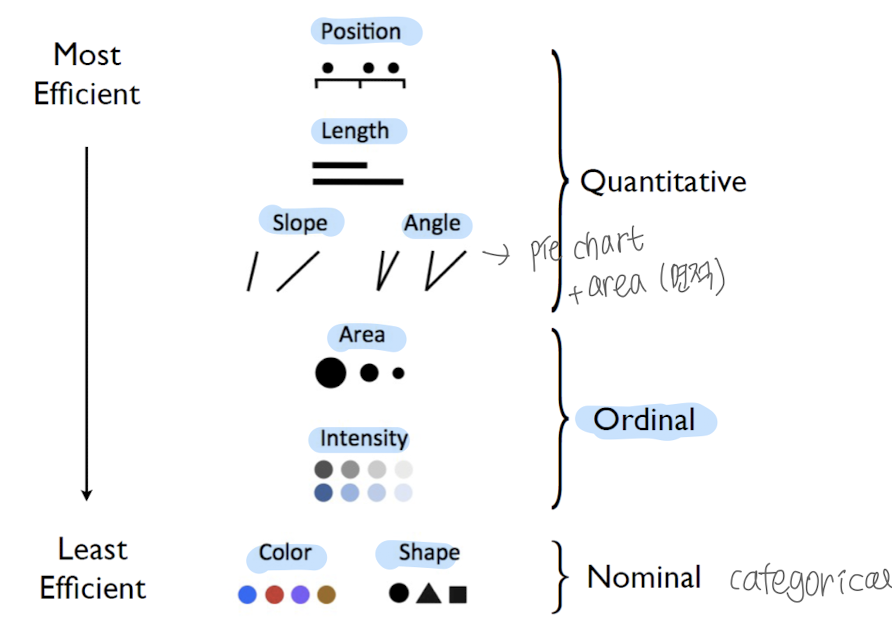
- 효율성 순위: 위치 > 길이 > 기울기, 각도 > 면적 > 색 진하기 > 색, 모양
- 면적, 색 진하기 데이터는 ordinal data에 사용 가능
- 원그래프는 면적과 각도를 같이 사용하지만, 도넛 그래프는 가운데가 비어있으므로 각이 생략된 형태다.
- 가장 비효율적인 시각화 사례
- 색의 우선순위를 결정
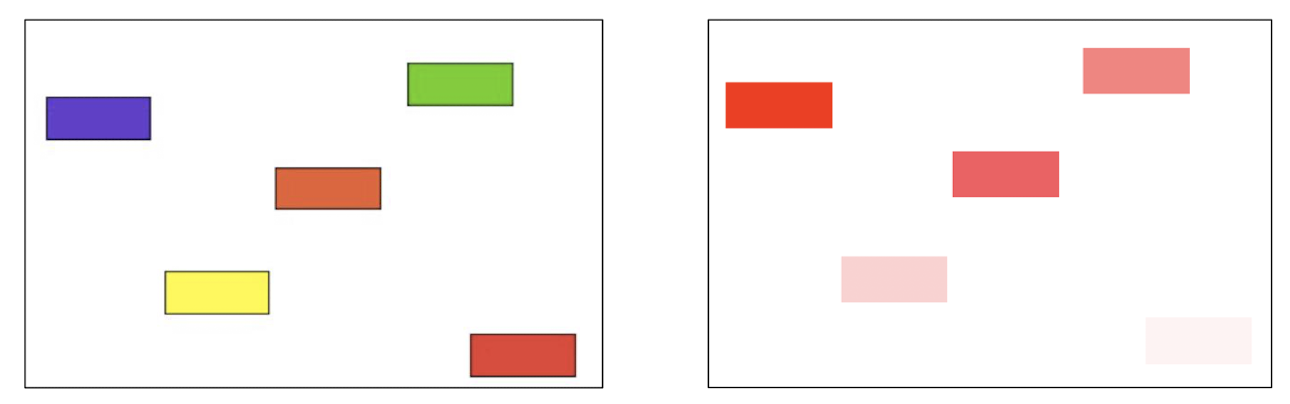
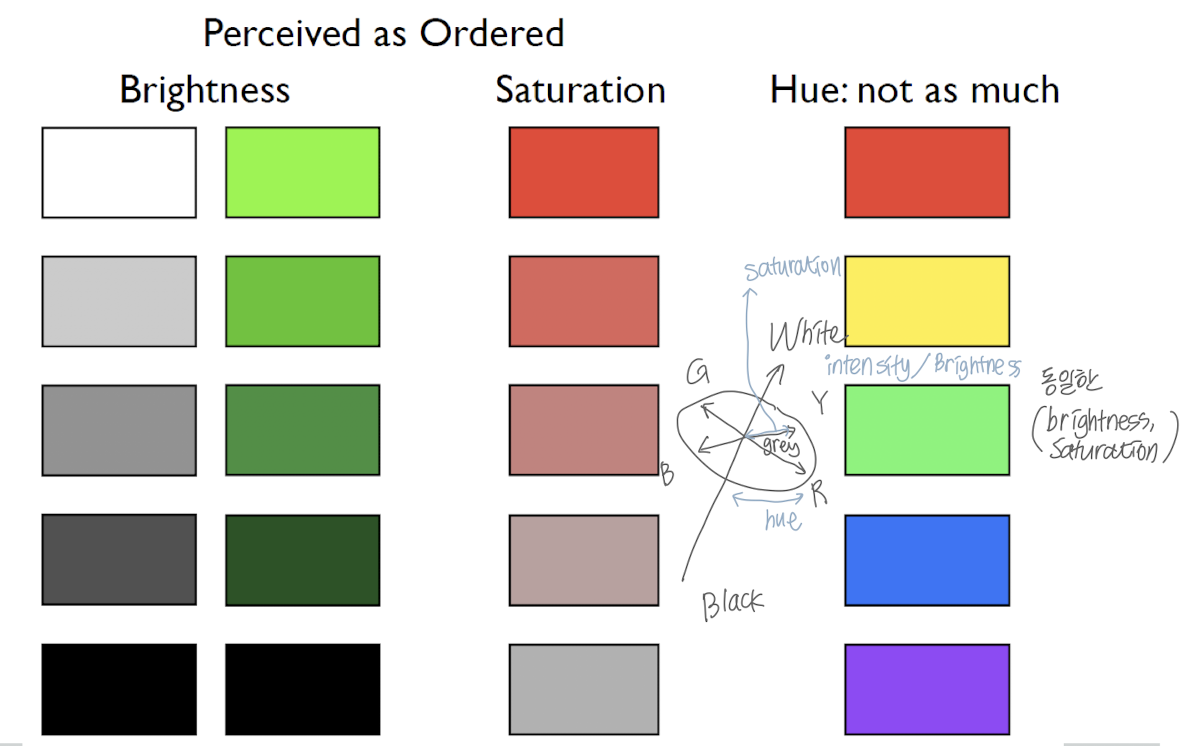
- 지나치게 복잡한 시각화는 좋지 않다. (하나의 그림에 너무 많은 정보를 담고 있는 경우, 색 순위를 구별하기 어려운 경우 등등)
Tufte's Design Principle
1. Maximize data ink-ratio
- data-ink ratio = data ink / total ink used in graphic
- 이 값이 최대한 1에 가까워져야 한다.
- 예시: 3D 막대 그래프를 2D로 변환하고, 그림자를 제거한다.
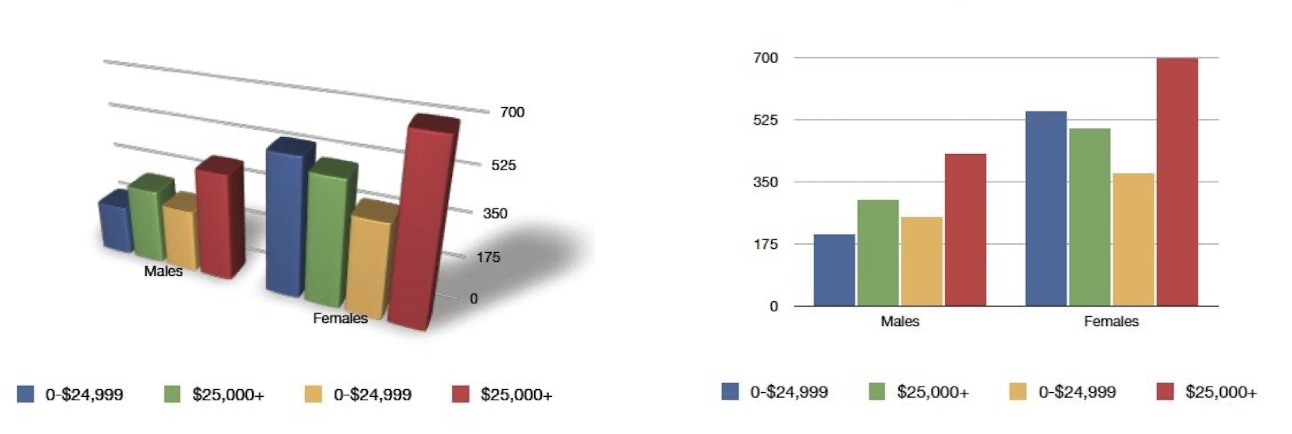
2. Minimize lie factor
- Lie factor = size of effect shown in graphic / size of effect in data -> 1에 가까워져야 한다.
- 실제보다 과장하여 그림을 그리는 경우
- 3D 그래프를 활용하여 값에 비해 그림이 더 커보이는 경우
3. Minimize chartjunk
- 불필요한 차원, 정보 전달용이 아닌 색 입히기, 과도한 격자무늬 및 데코레이션 등은 정보전달에 방해가 되는 요소.
- 격자 제거, 배경색 제거, 테두리 제거 등으로 시각화한 내용을 간단하게 만들자.
- 눈금의 경우 막대그래프 안에 표시하는 등 해서 더 줄일 수 있음.
- Matplotlib 등을 이용할 수 있다.
4. Use proper scales and clear labeling
- Scale Distortion: 눈금을 0부터 시작하지 않고 원하는 값에 포커스를 맞춰서 실제보다 차이를 더 크게 만들어버림.
ex) Bush Tax cuts expire~ -> 눈금은 항상 0부터 시작하도록 하자.
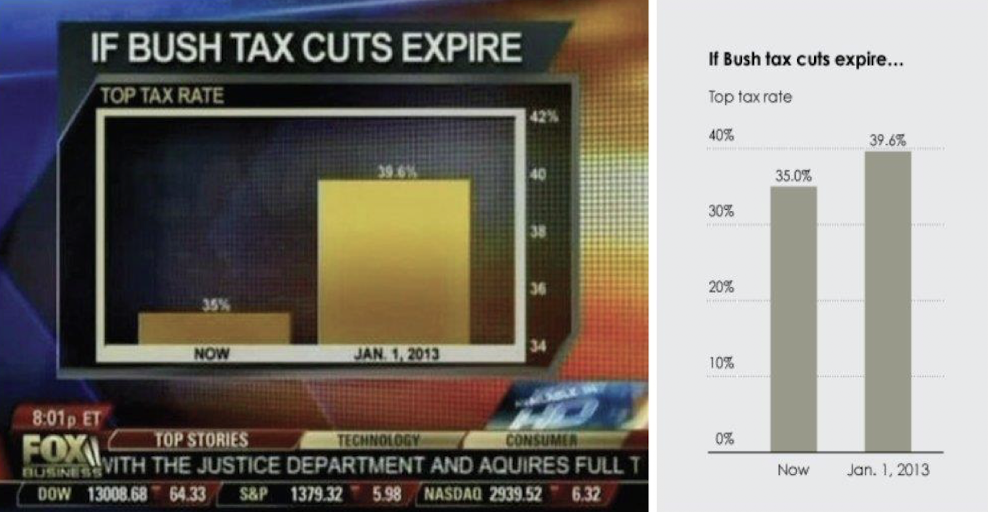
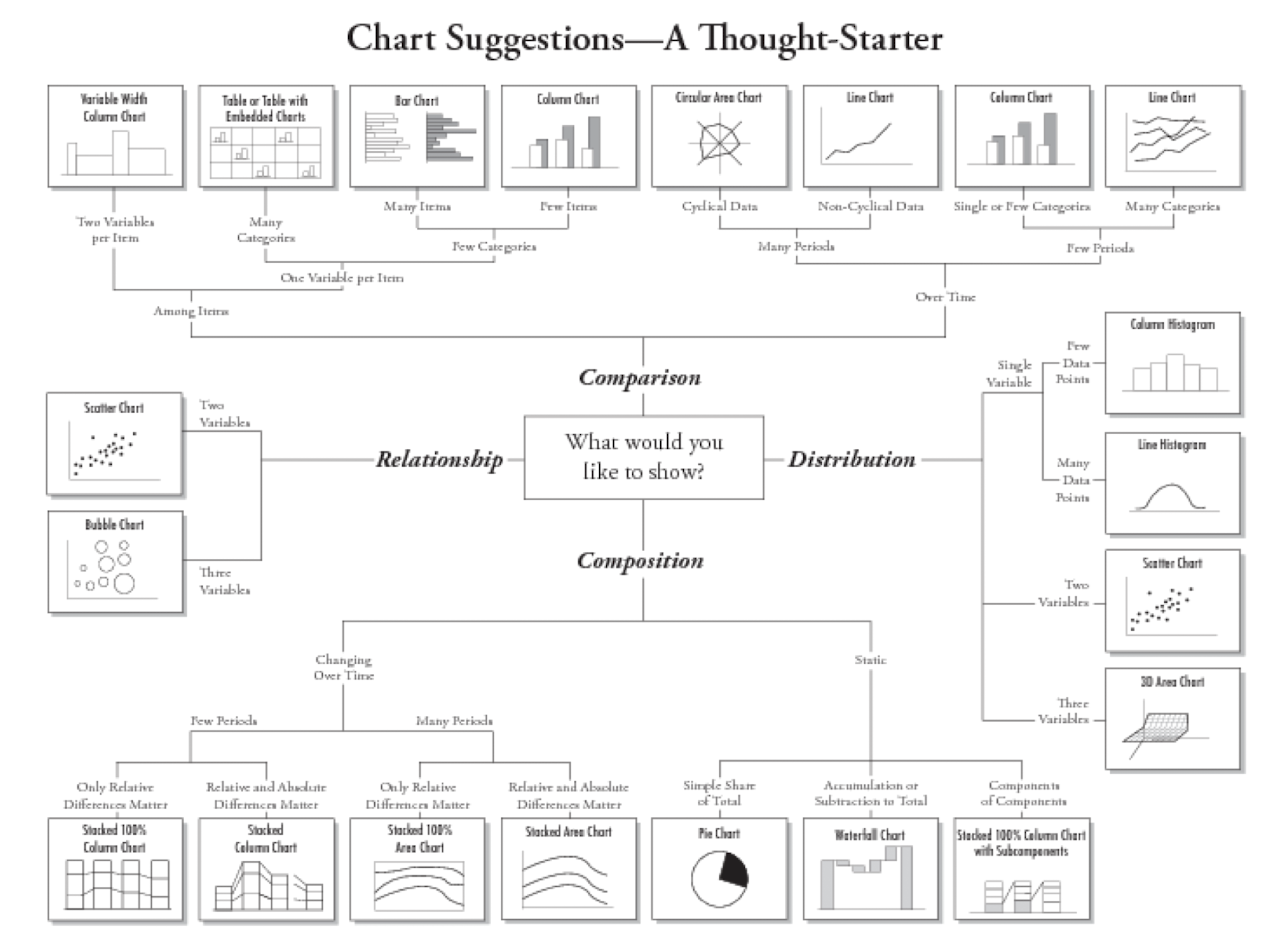
시각화 표의 종류
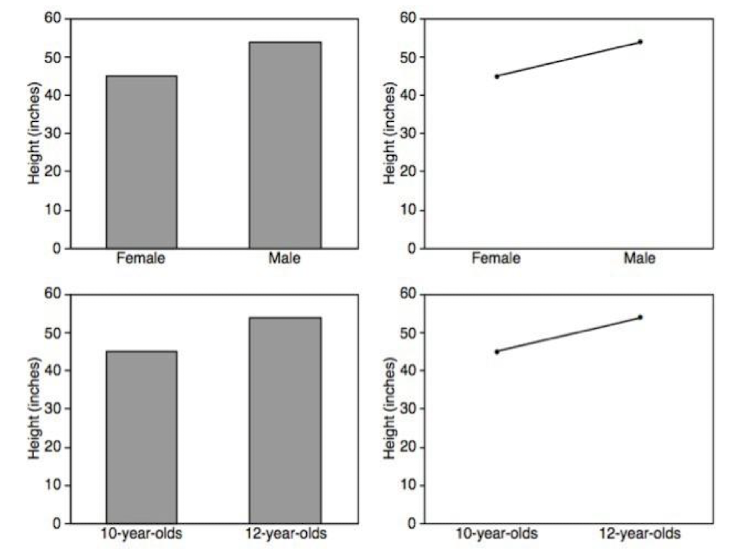
1. Bar Chart
2. Line Chart: 시간에 따른 트렌드의 변화
* Bar vs. Line: Line은 연결의 의미를 갖고 있으므로, Categorical data에 사용하면 안 된다.
* book rating을 비교하기 위해서 bar chart를 사용하지 마라.
* Banking to 45º: 2개의 line segment는 45도의 각에 가까워질수록 구별이 잘 된다.
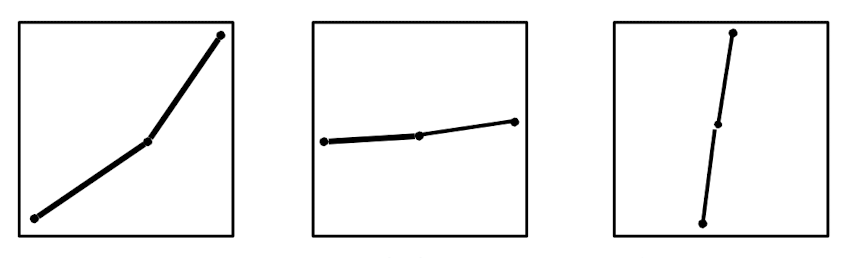
* 너무 플랫한 그래프나 stiff한 그래프를 그릴 경우 그래프를 잘못 해석하게 될 수 있으므로, 45도를 유지하자.
3. Scatter Plots / Bubble Charts
- Scatter plot은 각각의 점의 값을 2D에서 보여주는 데 효과적
- 3, 4개의 변수를 갖고 있는 데이터셋은 bubble chart를 이용
- principle component analysis를 통해 고차원의 데이터를 2D로 투영할 수 있다.
- 점의 크기가 너무 커지면 overplotting이 발생하므로 점의 크기를 줄이자.

- 점이 한 군데에 너무 몰리면 Overplotting이 발생하므로 불투명도를 낮추자.
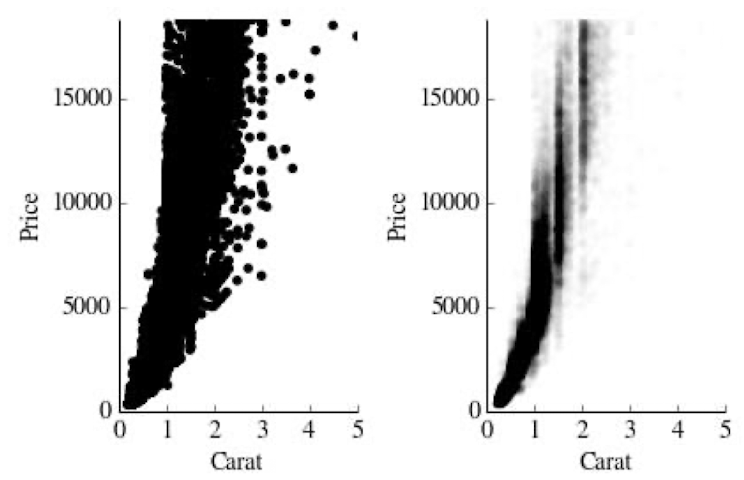
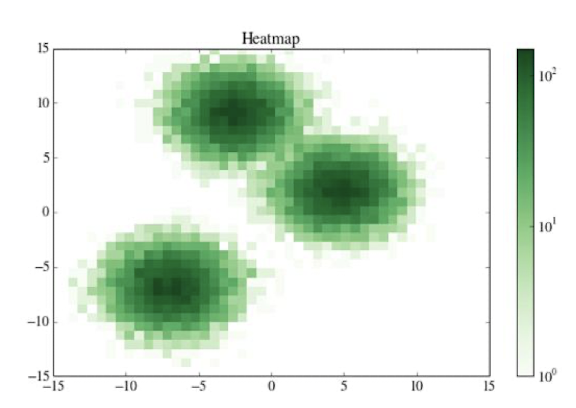
- heatmap: 빈도에 따라서 색을 달리하면 자료를 파악하기 더 쉽다.
- 점의 크기, 모양, 색을 달리하여 3차원의 자료를 시각화할 수 있다. -> Bubble Chart
* 3차원의 데이터라고 3D 공간에 나타내면 안 된다. 차원 축소를 하자.
4. Pie Chart
- Pie Chart vs. Bar Chart
* Pie Chart는 비율에 대한 질문에 대답하기 편리하다.
* Bar Chart는 실제 값에 대한 질문에 대답하기 편리하다.
5. Donut Chart
- 면적만 있으므로 pie chart에 비해 가독성이 떨어진다.
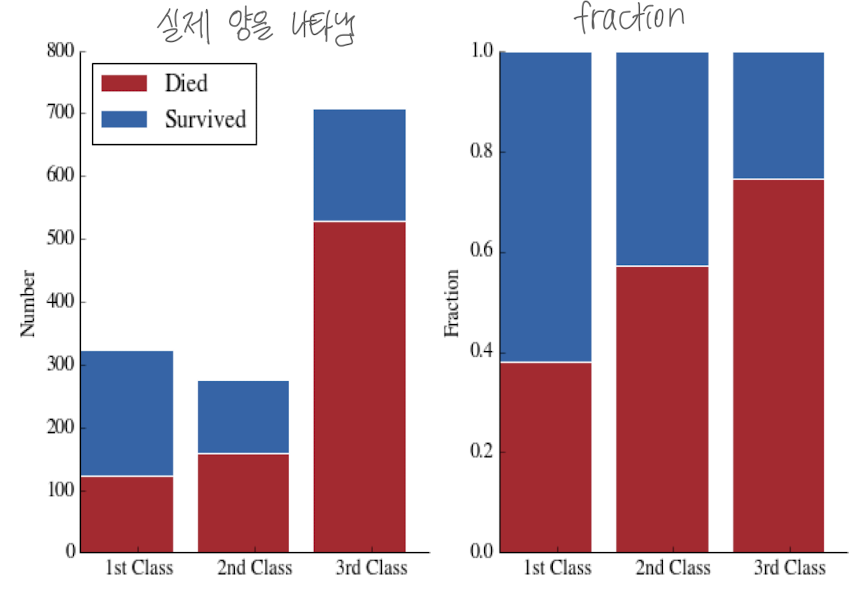
6. Stacked Bar Chart
7. Stacked Area Chart
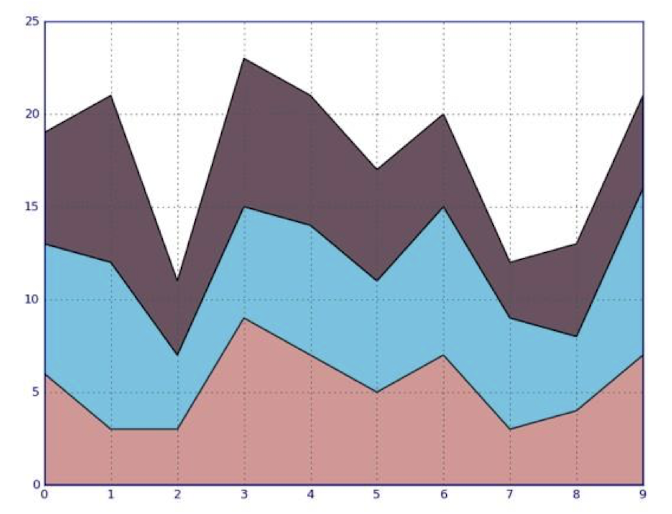
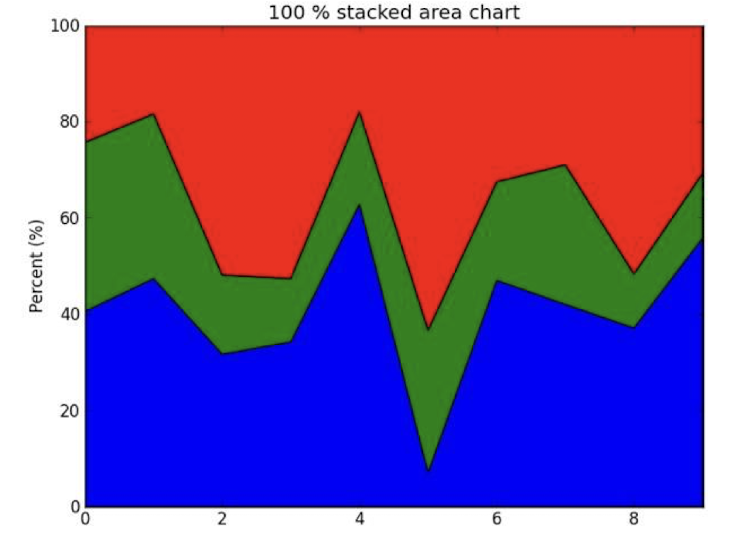
- Stacked Area Chart vs Line Graphs
* Stacked Area Chart에서는 각각의 성분이 차지하고 있는 비율 변화를 파악하기 쉽다.
* Line Chart에서는 각각의 성분의 절댓값을 파악하기 쉽다.
8. Histograms
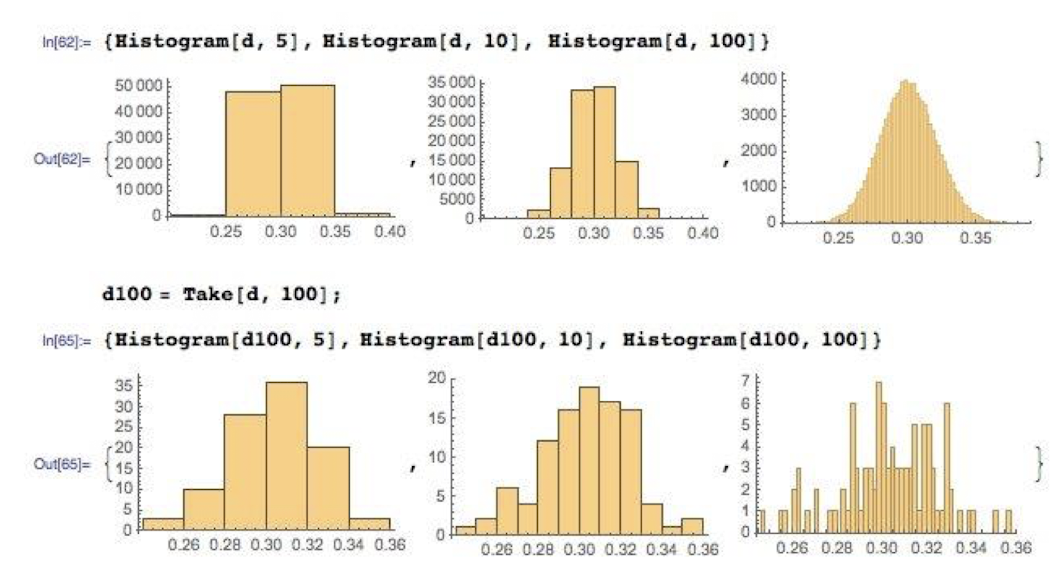
- Bin Size가 중요하다.
- Count가 중요하다.
- 너무 잘게 쪼개면 값의 분포가 잘 드러나지 않을 수도 있다.
- Frequency vs. Density Histograms
* 각 항목의 수를 전체 수로 나누면 확률 밀도 plot을 만들 수 있다. -> 더 해석하기 쉽다.
9. Heat Maps
10. Box & Whisker Plots
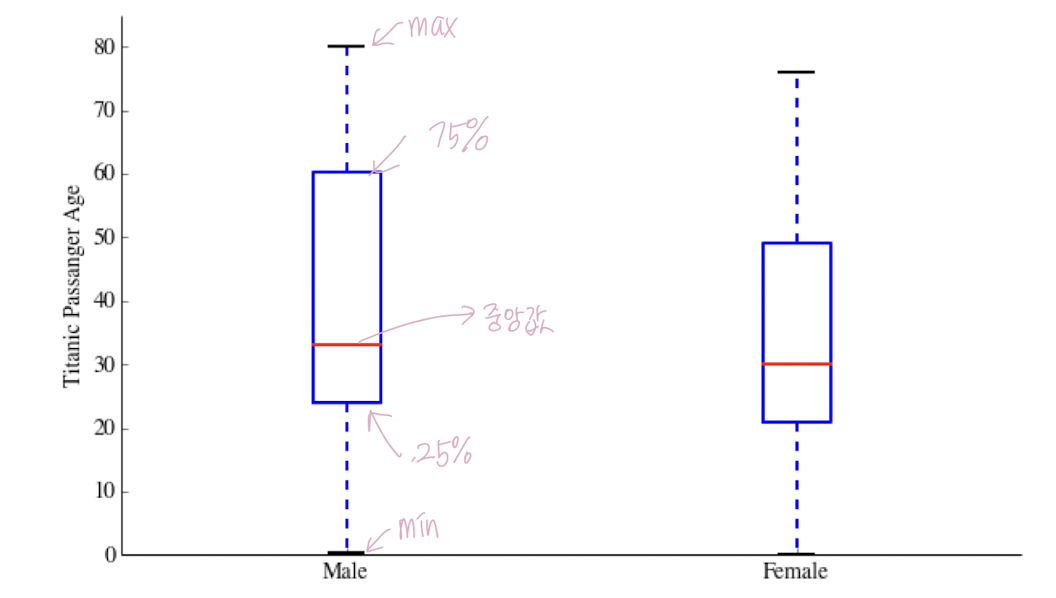
- max, min, 4분위수, 중앙값 등을 파악할 수 있는 자료
데이터 시각화를 위한 툴
- Excel: 가장 유명하지만 좋은 그래프를 만드는 것은 아님.
- R: 통계언어
- Matplotlib: 파이썬
Multivariate Data를 나타내기
- 작은 여러 개의 plot을 만들어서 표현하는 것이 좋은 방법이다.
- 예: 국가별 인구 분포 -> 국가별로 인구 분포를 만들어서 하나의 그림에 합친다.
Overinterpreting Variance
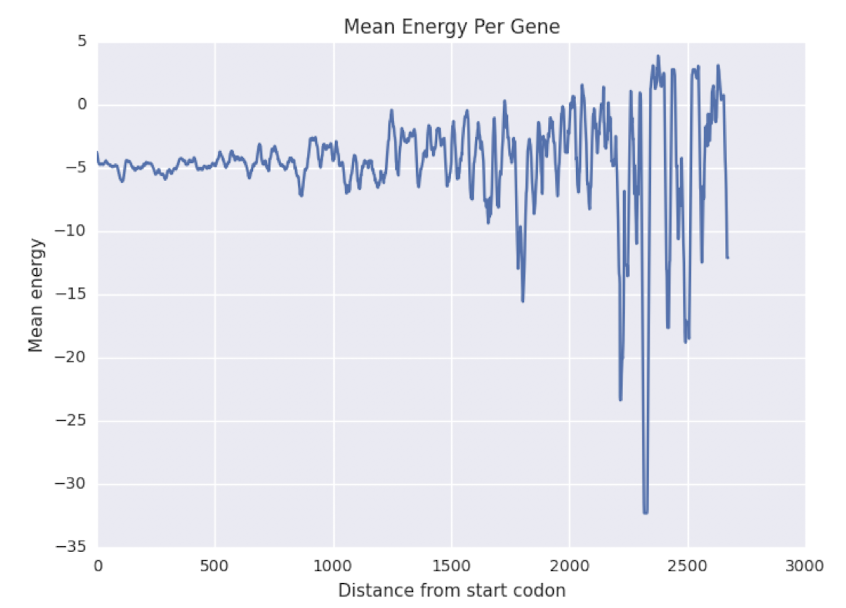
- 끝 부분 데이터가 요동치는 이유: gene마다 size가 모두 다르기 때문!
-> size가 큰 gene이 많지 않아서 경향을 파악하기 어려움.
비판적 시각으로 바라보기: 예쁜 데이터는 예쁜 시각화를 도출해낸다.



