무한스크롤 페이지에서 항목의 목록을 모두 수집하기 위해서는 스크롤 바를 맨 끝까지 내려야한다.
따라서 페이지를 내려도 계속해서 새로운 내용이 로딩되는 무한스크롤 웹페이지에서 스크롤 바를 계속해서 내리는 방법을 알아보자.
여러 가지 방법이 있는데, Keys.PAGE_DOWN를 사용할 수 있다.
1. 필요 라이브러리를 불러온다.
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
2. Keys.PAGE_DOWN을 사용하여 페이지 맨 끝에 도달할 때까지 스크롤 바를 내린다.
last_count = len(driver.find_elements(By.CSS_SELECTOR, 'a.contents__title')) # 현재 페이지에 로드된 리뷰 링크 수whileTrue:
body = driver.find_element(By.TAG_NAME, 'body')
body.send_keys(Keys.PAGE_DOWN)
time.sleep(1)
new_count = len(driver.find_elements(By.CSS_SELECTOR, 'a.contents__title'))
# 만약 새로운 링크가 더 이상 로드되지 않는다면 종료if new_count == last_count:
print("더 이상 스크롤할 수 없습니다.")
break
last_count = new_count # 개수 업데이트
body = driver.find_element(By.TAG_NAME, 'body')를 사용하여 body를 선택한 이후, send_keys 함수를 통해서 page down 키를 누르는 것과 동일한 효과를 준다.
이때, 무한루프를 사용해서 계속해서 스크롤을 내리기 때문에 무한루프 탈출 조건을 설정해야 한다.
나는 스크롤을 내려도 content의 개수가 바뀌지 않을 때 무한루프를 탈출할 수 있도록 조건을 설정하였다.
다이브 가을 기수 2주차 과제 - Audio Classification Model (오디오 분류 모델) 만들기 과제 하는 과정
간략하게 정리해보도록 하겠다.
우선, 나는 딥러닝을 그렇게 잘 아는 편은 아니라서 가장 쉬운 방법으로 과제를 해결하기로 하였고
그 과정에서 채택된 것이 바로 CNN 모델이다.
Tensorflow를 이용하였다. (학교에서 시키는 과제는 파이토치를 쓰기 때문에,, 텐서플로우는 처음이다)
1) 오디오 데이터 불러오기
사용한 데이터 설명은 다음과 같다.
14개의 악기들별 소리가 저장되어 있는 데이터셋입니다. 오디오를 MFCC 계수의 개수를 13개로 설정한 MFCC 형태로 전처리했으며 전처리 방식은 아래와 같습니다. 전체 데이터셋에서 무작위로 하나의 악기를 고르고, 해당 악기 레이블의 데이터 중 랜덤하게 파일을 골라 그 음성 파일 내에서 공백 부분을 제외하고 0.5초를 샘플링하는 과정을 전체 데이터셋에 대해 56789번 반복했습니다. 데이터의 형태는 다음과 같습니다. 데이터는 어떤 정규화나 표준화도 거치지 않았습니다.
데이터의 형태는 넘파이로 저장되어 있었기 때문에 넘파이를 이용해 불러와준다.
import numpy as np
Xdata = np.load("Xdata.npy")
ydata = np.load("ydata.npy")
그 후, 필요한 모듈들을 임포트 해온다.
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
from sklearn.model_selection import train_test_split
# 모델 컴파일
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# 모델 학습
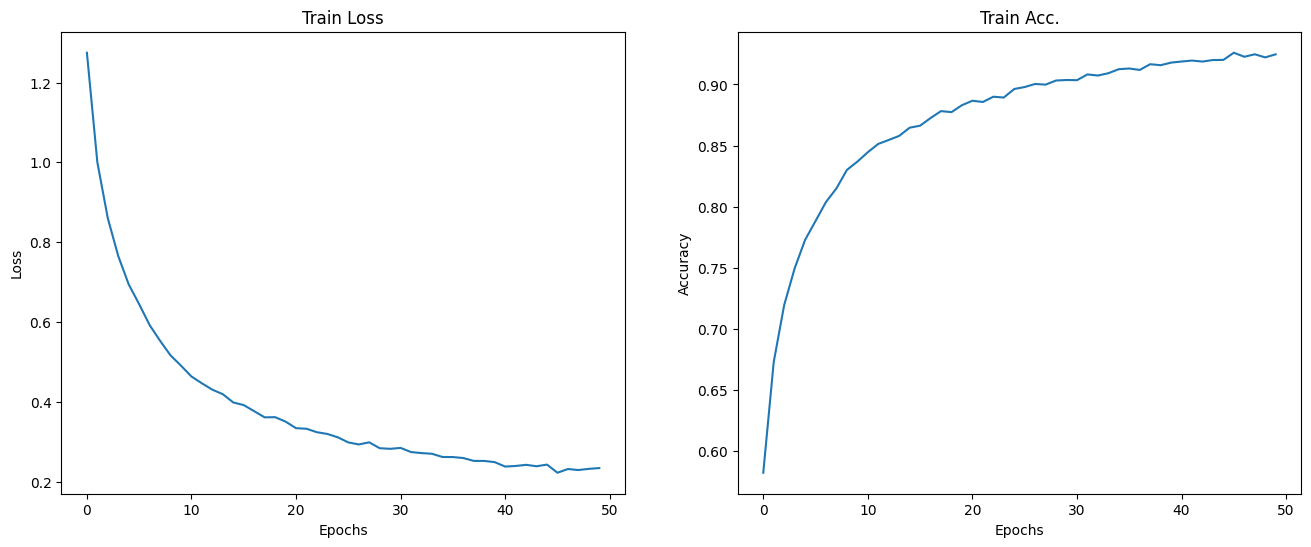
history = model.fit(X_train, y_train, epochs=50, batch_size=64)
모델 학습을 위와 같이 진행한다. 에포크 수는 처음에 20으로 했다가 수렴이 안됐길래 더 크게 해줬다.