

이번 포스팅에서는 카테고리 (범주형) 자료 인코딩 방법 중 하나인 Mean Target Encoding에 대해 소개하고자 한다.
사실 나는 범주형 변수 인코딩 방법에 라벨인코딩과 원 핫 인코딩만 있는 줄 알았다.
그런데 이번 채무불이행 데이터를 분석할 때 내가 했던 절차들이 사실은 Mean Target Encoding이었다는 것을 알게 되어 놀랄 수밖에 없었다.
아무튼 본론으로 들어가자.
범주형 변수가 무엇인지는, 이전에 내가 작성하였던 글을 참고하면 좋을 것 같다.
https://iamnotwhale.tistory.com/5
[EDA] 데이터 종류별 시각화 방법
데이터의 종류 데이터는 크게 범주형, 수치형 두 가지 분류로 나눌 수 있다. 범주형 데이터는 범주/카테고리를 구분하는 각각의 이름을 갖는 데이터 종류다. ex) 성별 - 여성, 남성 / 학력 - 초졸,
iamnotwhale.tistory.com
간단히 말하자면, 범주형 변수는 범주/카테고리로 나눌 수 있는 데이터들이다.
예를 들어 성별이라는 데이터는 여성 또는 남성으로 분류될 수 있으므로 범주형 변수다.
범주형 변수의 하위 분류로 명목형 (여성, 남성), 순위형 (1등, 2등, 3등...) 을 분류할 수 있지만 이 글에서는 몰라도 된다.
범주형 변수는 대개 판다스 데이터프레임에서 object 형태로 주어진다. 이를 그대로 머신러닝 알고리즘에 투입할 수 없다. 왜냐하면 컴퓨터는 여성/남성이 무엇인지 구별할 수 없기 때문이다. 오로지 숫자 형태로 주어졌을 때만 해석할 수 있다.
따라서 우리는 컴퓨터가 이해할 수 있는 숫자 (int, float) 형태로 변환해야 하며, 이에 사용되는 것이 인코딩이다.
범주형 변수의 인코딩 방법으로는 여러가지가 제시될 수 있지만, 가장 대표적인 것은 Label Encoding, One-Hot Encoding일 것이다.
Label Encoding은 단순하게 여러 카테고리에 번호를 매긴다. 이 번호는 무엇이 더 낫고 별로이고 이런 정보를 갖지는 않는다. 그냥 1번 그룹, 2번 그룹 이런 느낌이라고 생각하면 된다.
하지만 이는 트리를 제외한 일반적인 머신러닝 알고리즘에서 좋은 성능을 내기 어렵기 때문에 자주 사용하지 않는다.
One-Hot Encoding은 하나의 칼럼만 Hot, 나머지는 Cold하다는 의미를 담고 있다.
무슨 뜻인지 바로 감이 안 올 수도 있어 다시 정리하자면, 범주형 변수 값들을 각각 새로운 컬럼으로 생성하고, 이 컬럼에 해당하는 속성을 가질 때 1, 아닌 건 전부 0으로 표시하는 것이다.
표로 설명하겠다.
| ID | Color |
| 0 | Pink |
| 1 | Yellow |
| 2 | Pink |
| 3 | Blue |
이런 데이터가 있을 때, Color 칼럼에 원 핫 인코딩을 적용하면 다음과 같이 데이터프레임이 변환된다.
| ID | Color_Pink | Color_Yellow | Color_Blue |
| 0 | 1 | 0 | 0 |
| 1 | 0 | 1 | 0 |
| 2 | 1 | 0 | 0 |
| 3 | 0 | 0 | 1 |
Color의 데이터 정보를 가지는 열을 각각 생성하여 정보를 나타낼 수 있다.
원 핫 인코딩은 라벨인코딩에 비해 성능은 높지만, 범주형 변수 값이 너무 많을 경우 차원이 지나치게 커져 성능이 낮아질 수 있다.
그럼 Mean Target Encoding은 어떨 때 사용하는가?
위에서 소개한 두 인코딩 방법은 단순히 분류에만 사용하고, Target과의 관계를 강조할 수 없다.
원 핫 인코딩의 경우 값이 많아지면 차원이 지나치게 커지는 문제도 있다.
이러한 문제들을 해결하기 위해 Mean Target Encoding을 이용한다.
간단하게 소개하자면 해당 칼럼의 같은 라벨을 갖고 있는 데이터들의 Target 값의 평균으로 인코딩할 수 있다는 것이다.
데이터를 그대로 올릴 수는 없겠지만, 채무불이행 데이터 중에는 Loan Title이라는 칼럼이 있고,
해당 칼럼의 라벨은 굉장히 다양하다.
'Credit card refinancing', 'Debt consolidation',
'Credit card refinance', 'Credit Card Consolidation',
'Debt Consolidation', 'Home improvement', 'Consolidation', 'Other',
'relief', 'debt consolidation loan', 'Major purchase', 'Loan',
'credit card refinance', 'Medical', 'Pool', 'Vacation',
'CC consolidation', 'Medical expenses', 'Moving and relocation',
'payoff', 'Personal Loan', 'debt consolidation', 'Debt Loan',
'House', 'consolidation loan', 'consolidate', 'Credit payoff',
'Bathroom', 'Green loan', 'Debt Payoff', 'Consolidate', 'Business',
'Lending Club', 'Refinance', 'Home Improvement',너무 많아서 그냥 이정도만 갖고 왔다.
이러한 라벨들에 따라서 target (이 채무불이행 데이터의 경우 loan status) 값의 비율, 즉 평균을 구하고자 했다.
(평균은 값의 합/값의 개수인데, target이 0, 1로 구성되어 있기 때문에 평균이 데이터에서 1의 비율과 같아진다)
코드는 다음과 같이 작성했다.
# 데이터 불러오기
df = pd.read_csv("train_loan.csv")
# Target과 변수만 불러오기
data = df[['Loan Title', 'Loan Status']]
# Mean Target Encoding
ratio = pd.DataFrame(data.groupby('Loan Title').mean()).reset_index()
# 인코딩 결과 시각화
ratio.sort_values(by = 'Loan Status').plot.bar()
plt.show()ratio라는 데이터프레임 칼럼에서 Loan Title 칼럼을 기준으로 groupby 메서드로 묶고, mean() method를 이용하여 Mean Target Encoding을 진행하였다.
시각화 결과는 다음과 같았다.
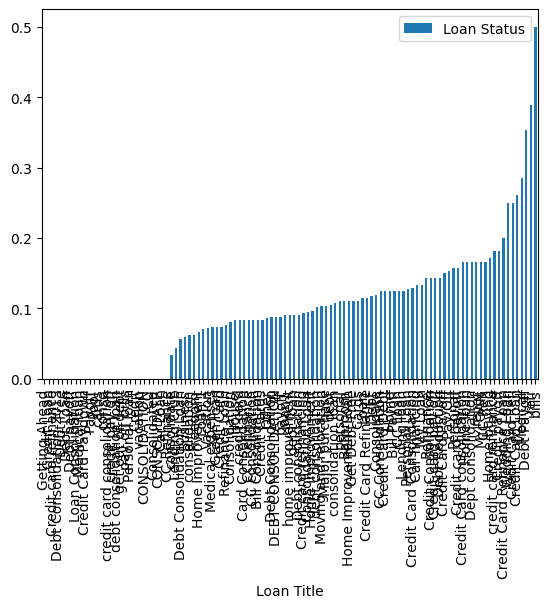
인코딩 결과로 클러스터링을 진행하거나 그대로 이용하면 된다.
나는 클러스터링까지 진행했다.
from sklearn.cluster import KMeans
inertia = []
for i in range(1, 11):
kmeans_plus = KMeans(n_clusters = i, init = 'k-means++')
kmeans_plus.fit(ratio)
inertia.append(kmeans_plus.inertia_)
plt.plot(range(1,11), inertia, marker = 'o')
plt.xlabel('Number of clusters')
plt.ylabel('Inertia')
plt.show()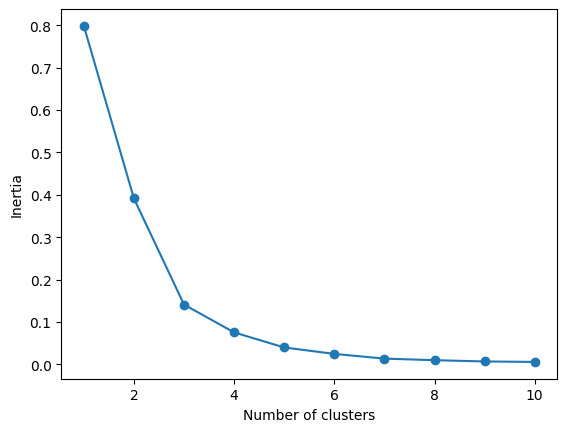
elbow method로, 클러스터 개수는 3개로 정하였다.
기존에 알고 있던 인코딩과 가장 큰 차이점은 Target 변수와의 관계까지 인코딩 과정에서 나타내고자 했다는 점이다.


