

머신러닝 모델의 비교
- Power, expressibility: 얼마나 복잡한 작업을 할 수 있느냐
- Interpretability
- Ease of Use
- Training speed
- Prediction speed
| Linear Regression | Nearest Neighbor | Deep Learning | |
| Power/Expressibility | L | L | H |
| Interpretability | H | H | L |
| Ease of Use | H | H | L |
| Training speed | H | H | L |
| Prediction speed | H | L | H |
cf) 딥러닝은 Foward Fast를 이용한다. Nearest Neighbor는 거리 계산 때문에 연산 시간이 길다.
XOR & Linear Classifier
- Linear Classifier는 XOR 같은 간단한 비선형함수를 적합시킬 수 없다.
- 대안: Decision tree, Random forest, Support Vector Machines, Deep Learning
Decision Tree Classifier
- root->leaf path를 통과하면서 분류가 되는 모델
- 트리는 학습 예시들을 비교적 균일한 구성으로 분해

- Top-down manner로 구성
- m개의 클래스들에 대한 정보를 정제하기 위해 1개의 피쳐/차원을 따라 분리
* pure split: 1개의 단일 클래스 노드 생성
* balanced split: group 크기가 대략적으로 비슷하도록 항목을 분리

Information-Theoretic Entropy
- entropy: class confusion의 양을 측정
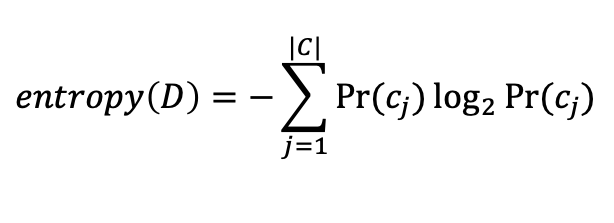

Split Criteria
- information gain
gain(D, A_i) = entropy(D)-entropy_{A_i}(D)

- 이용: 데이터 칼럼별로 계산해서, 가장 값이 큰 것을 선택해야 잘 나눌 수 있음.
Stopping Criteria
- information gain이 0이 될 때가 아니라, 입실론보다 작다면 멈춰도 된다. -> 이정도면 충분하다는 뜻
- alternate strategy: full tree를 만들어서 low value node를 가지치기 하기
-> subtree중 의미가 거의 없는 부분을 leaf로 통일한 후, 원래 트리와 성능을 비교하여 채택
Decision Tree의 장점
- 비선형성
- categorical variable을 잘 적용
- 설명 가능성 높음
- robustness: 다른 트리들과의 앙상블을 진행해서 더 나은 것을 vote할 수 있음
Ensemble Methods
1. Bagging
training
- k개의 bootstrap sample 생성
- 각각의 S[i] 샘플에 대해 classifier를 생성해서 k개의 classifier를 만듦 (같은 알고리즘 이용)
testing
- k개의 classifier를 동일한 가중치로 투표해서 새로운 사례들을 분류해보기
2. Boosting
training
- classifier의 sequence를 생성 (같은 base learner 이용)
- 각각의 classifier는 이전 classifier에 의존적이며 그것의 에러를 찾는 데 집중
- 이전 classifier에서 잘못 예측된 사례들은 더 높은 가중치를 부여
testing
- classifier들의 연속으로 판단된 결과를 결합하여 test case의 최종 클래스를 부여
Random Forest
- Bagging with decision tree + split attribute selection on random subspace
-> learning process에서 나뉜 후보자들 각각을 선택하여 학습한 변형 트리 알고리즘 사용 -> random subset of features
* 1단계: bootstrapped dataset 생성

* 2단계: decision tree 생성 -> 각 단계의 피쳐의 random subset만을 이용한 bootstrapped dataset을 이용해야 함
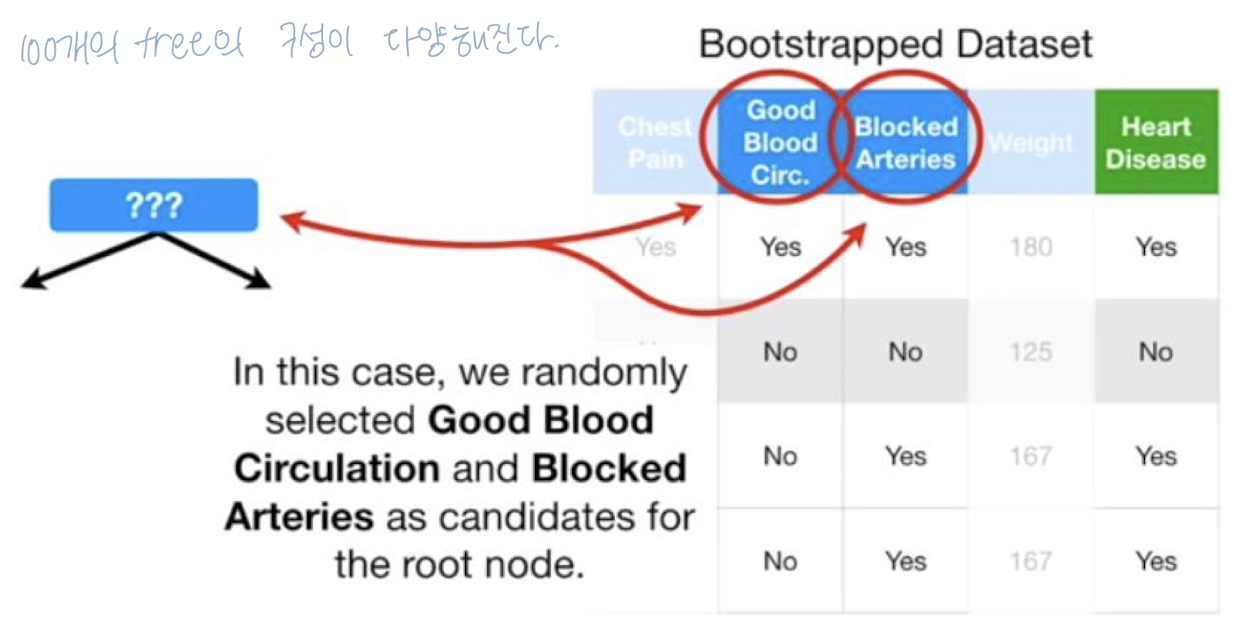
- 새로운 노드에서도 root처럼 랜덤으로 두개의 변수를 candidate로 선택 (전체 3개의 column중 1개는 무시)

* 3단계: 반복 - 반복을 통해 새로운 트리를 계속 생성
* 4단계: Inference
- 가장 투표를 많이 받은 옵션이 무엇인지 확인
* 정확도 측정
- 통상적으로 원본 데이터의 1/3은 bootstrapped dataset에 나타나지 않음
-> 이 데이터(Out-Of-Bag sample)로 validation을 진행
Support Vector Machines
- 비선형성 분류기를 만드는 중요한 방법
- 2개의 클래스 사이에서 maximum margin linear separator를 추구
SVM vs Logistic Regression
- 공통점: seperating plane
- 차이점: LR는 모든 값에 대해서 평가하지만, SVM은 경계에 있는 점만 확인함
- SVM: 기본적으로 선형적이지만 더 고차원에도 적용할 수 있다.
고차원으로의 projection
- 차원 수를 늘리면 모든 것을 linearly separable하게 만들 수 있다.

Kernels and non-linear functions

Feature Engineering
- domain-dependent data cleaning은 중요하다
* Z-scores, normalization
* bell-shaped distribution 생성
* missing value를 imputing
* 차원축소 (SVD) -> 노이즈 말고 중요한, y값을 예측할 수 있는 아주 작은 신호 정보들을 뭉개버릴 수 있어 performance에 문제가 생길 수 있다.
* non-linear combination의 explicit incorporation (ex. products, ratios...)
Nerual Networks




