

데이터의 종류
데이터는 크게 범주형, 수치형 두 가지 분류로 나눌 수 있다.
범주형 데이터는 범주/카테고리를 구분하는 각각의 이름을 갖는 데이터 종류다.
ex) 성별 - 여성, 남성 / 학력 - 초졸, 중졸, 대졸, 대학원졸 / 출신 학교 - 고려대학교, 연세대학교, ...
반면 수치형 데이터는 말그대로 숫자로 표시되는 자료들이다.
ex) 나이 - 1살, 2살, ... / 키 - 160cm, 161cm, ... / 몸무게 - 50kg, 51kg, ...
범주형 데이터(질적 자료)
범주형 데이터는 또 순위형, 명목형이라는 두 가지 하위 분류로 다시 나누어진다.
순위형 데이터는 각 데이터별로 순위가 나누어져 있는 데이터들이다.
예를 들어 만족도 데이터를 생각해보면, 5점과 1점은 동등한 자격을 갖는 데이터가 아니다. 보통 5점이 1점보다 더 높은 순위를 가지기 때문이다. 따라서 만족도 데이터는 순위형 데이터이다.
명목형 데이터는 반대로 각 데이터별 순위가 없는 데이터이다.
성별 데이터는 여성과 남성으로 이루어지는데 둘 사이의 순위를 매길 수 없으므로 명목형 데이터이다.
수치형 데이터(양적 자료)
수치형 데이터 역시 이산형, 연속형이라는 두 하위 분류로 나눌 수 있다.
이산형 데이터는 데이터와 데이터 사이에 끊어짐이 있다.
물건의 개수와 같은 예시를 들 수 있다. 1개와 2개 사이인 개수를 정의할 수 없으므로 물건의 개수는 이산형 데이터이다.
반면 연속형 데이터는 데이터와 데이터 사이에 끊어짐이 없다.
키는 160cm와 161cm 사이에 무수히 많은 값을 가질 수 있으므로, 연속적이라고 볼 수 있으며 따라서 연속형 데이터에 해당한다.
범주형 데이터 시각화
범주형 데이터를 시각화하기 위해서 seaborn, matplotlib을 이용한다.
import seaborn as sns
import matplotlib.pyplot as plt상단의 파일을 사용하였다.
1) 범주형 변수 1개
범주형 변수를 시각화하기 위해서 막대그래프나 원그래프를 그릴 수 있다.
막대그래프의 경우 pandas의 기능 중 하나인 plot.bar()를 사용할 수 있다.
image = df['grade'].value_counts().plot.bar()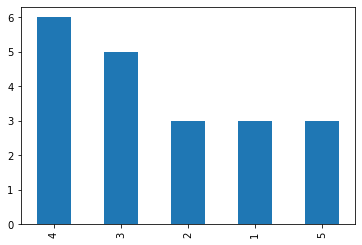
막대그래프를 그리는 다른 방법에는 seaborn의 카운트도표 sns.countplot()이 있다.
sns.countplot(x = 'grade', data = df)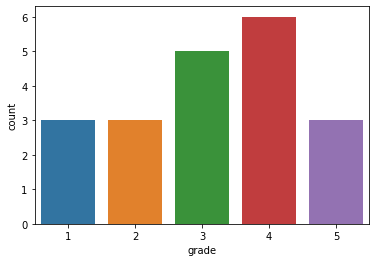
원그래프는 plt.pie()를 이용한다.
plt.pie(x = df['grade'].value_counts(), labels = [1, 2, 3, 4, 5], autopct='%.1f%%')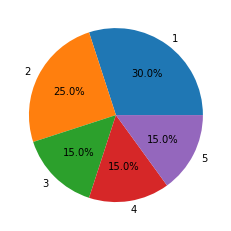
2) 범주형 변수 + 수치형 변수 시각화
① sns.lineplot(): 명목형 + 수치형(연속형 + 이산형)
② sns.scatterplot(): 명목형 + 수치형(연속형 + 연속형)
③ sns.barplot(): 명목형 + 연속형
④ sns.pointplot(): 명목형 + 연속형
⑤ sns.boxplot(): 명목형 + 연속형
⑥ sns.violinplot(): 명목형 + 연속형
굉장히 다양한 방법으로 시각화가 가능하므로 때에 따라 적절하게 시각화 방법을 고르면 된다.
이중에서 scatterplot을 한 번 그려보자.
sns.scatterplot(x = 'weight', y = 'height', data = df, hue = 'grade')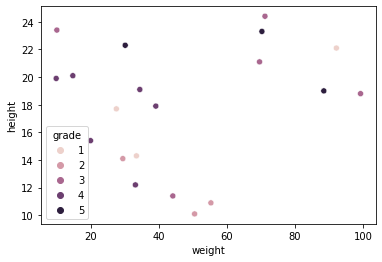
weight와 height 사이의 scatterplot을 그렸지만, hue를 통해 grade별로 다르게 표시하였다.
grade는 범주형 변수이고 나머지는 수치형이므로 범주형, 수치형 사이 데이터를 시각화하는 방법이 될 수 있다.
수치형 데이터 시각화
1) 수치형 변수 1개
히스토그램을 그려서 수치형 변수를 시각화해보자. plt.hist()를 이용할 수 있다.
plt.hist(df['height'])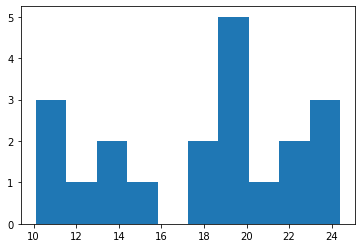
구간의 개수는 hist의 인자인 bins에 값을 넣어주면 된다.
히스토그램에 확률밀도함수를 추가하여 그리는 방법도 있다. sns.displot()를 이용하면 다음과 같다.
sns.distplot(df['weight'])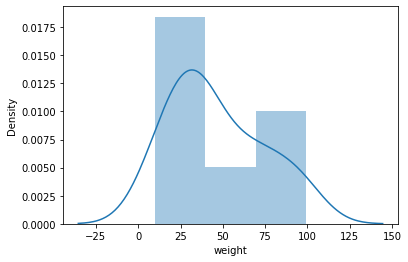
sns.boxplot()을 통해 박스플롯을 그릴 수 있다. min, max, Q1, Q2, Q3, outlier를 확인할 수 있다.
plt.figure(figsize = (6, 8))
sns.boxplot(y = 'weight', data = df)
plt.show()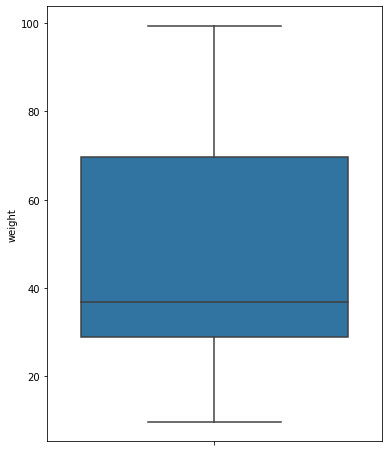
2) 수치형 변수 2개
① sns.lineplot(): 연속형 + 이산형
② sns.scatterplot(): 연속형 + 연속형
③ sns.regplot(): 연속형+ 연속형
다양한 방법으로 시각화가 가능하다. 어떤 방법으로 시각화를 했을 때 데이터가 가장 잘 드러나는지는 연습해볼 필요가 있는 것 같다.


